Calculating the Fibonacci numbers
The Fibonacci sequence is defined as the sequence that satisfies the following properties:
- It starts with 0, 1
- Every subsequent term is the sum of the two preceding terms
So, it starts as 0, 1, 1, 2, 3, 5, 8, 13, ...
Mathematically, it is defined as
Now, let's write a fast Python function to calculate the th Fibonacci number. (Python is not normally a language I'd use to write something that needs to be fast, but this is just for fun. In this case I choose it because its built-in big number support is so convenient. It could also be written in, say, C++, although you'd need something like boost to provide the support for big numbers.)
A naive implementation
Naively, we can code the mathematical definition into a recursive function:
def fibonacci_naive(n):
if n <= 1:
return n
return fibonacci_naive(n - 1) + fibonacci_naive(n - 2)
However, it turns out that this is very slow, even just calculating already takes more than a second on my machine. Even worse, the runtime of fibonacci_naive(n) seems to increase very rapidly when we increase n: calculating already takes more than five seconds.
If we think about this function a bit, we can see that the only way the recursion can "end", is when it returns 0 or 1. So to calculate , at least function calls need to be made. Now, turns out to be exponential as a function of . The runtime of fibonacci_naive(n) is at least exponential in n.
A simple and fast implementation
Noting that
we can come up with the following simple algorithm:
def fibonacci_linear(n):
f_n, f_nm1 = 0, 1
for _ in range(0, n):
f_n, f_nm1 = f_n + f_nm1, f_n
return f_n
This is blazing fast compared to the naive algorithm. Calculating , a number with 2090 digits, takes about a millisecond on my machine.
We note that the number of operations that fibonacci_linear(n) does is linear in n. However, since the length of the numbers involved is also linear in n, the runtime is quadratic. Usually you want to steer clear of quadratic algorithms, but this particular algorithm is probably good enough for most applications.
Using matrices
If we really want to be a tryhard we can note that we can turn the recursive definition into a matrix equation:
So now we want to calculate the exponential of a matrix. This can be done in operations by using the Russian peasant algorithm (which is typically presented as an algorithm for multiplication, but it works for exponentiation as well if we replace the doubling by squaring and the addition by multiplication).
The idea is that to compute we loop over the bit positions b = 0, 1, 2, ... of n and keep in a variable temp. To find , we can simply square . Then we have an accumulator acc that is initialized to 1 (or the identity matrix, or whatever), and we multiply it by whenever the bit at position b in n is set. When the function terminates, we have
in the accumulator variable acc. I used to denote the bit positions that are 1 in the binary representation of , so that .
Putting this together we get
class Matrix:
def __init__(self, a, b, c, d):
self.a, self.b, self.c, self.d = a, b, c, d
def __mul__(self, other):
return Matrix(self.a * other.a + self.b * other.c,
self.a * other.b + self.b * other.d,
self.c * other.a + self.d * other.c,
self.c * other.b + self.d * other.d)
def russian_peasant_exponentiation(x, n, id):
acc = id
temp = x
while n > 0:
if n & 1:
acc *= temp
temp *= temp
n >>= 1
return acc
def fibonacci_matrix(n):
fibonacci_matrix = Matrix(1, 1, 1, 0)
identity_matrix = Matrix(1, 0, 0, 1)
return russian_peasant_exponentiation(fibonacci_matrix, n, identity_matrix).b
Granted, this could be optimized further by inlining and simplifying things, but doing so would destory the whole idea of using a matrix, and we're going to simplify everything by using some mathematical identities anyway in the next section.
Micro-optimizing using math
Now we note that
and
We see here that the entry in the right top of the right matrix is calculated as even though is already in the matrix on the left. From this we already see that the previous algorithm, which uses this exact algorithm, is not optimal.
From these two identities, it follows by induction that
Using we see
Looking at the element in the left top and the element in the right bottom of the left and right side, we obtain the identities
If we set we get
Now, if we work with pairs of the form , we know how to "double" the index (e.g. obtain from ), and how to "add" (e.g., obtain from and ). So we can use the Russian peasant multiplication algorithm again. Factoring out some common expressions, we get:
def fibonacci_fast(n):
acc = (0, 1)
temp = (1, 0)
while n > 0:
if n & 1:
square = acc[0] * temp[0]
acc = (square + acc[0] * temp[1] + acc[1] * temp[0],
square + acc[1] * temp[1])
square = temp[0] * temp[0]
temp = (square + 2 * temp[0] * temp[1],
square + temp[1] * temp[1])
n >>= 1
return acc[0]
And this is the fastest code I could write to calculate the Fibonacci numbers (in Python, that is). It's runtime should be comparable to the runtime fibonacci_matrix since it's still using the Russian peasant exponentiation scheme. However, it should be a bit faster since we got rid of a lot of overhead (function calls, lists, duplicate computations).
Benchmarks
Note that both axes are logarithmic. In this type of graphs, graphs of the form map to a straight line. Two graphs and have the same slope if the exponents and are the same. They have a vertical offset if the constants and are different.
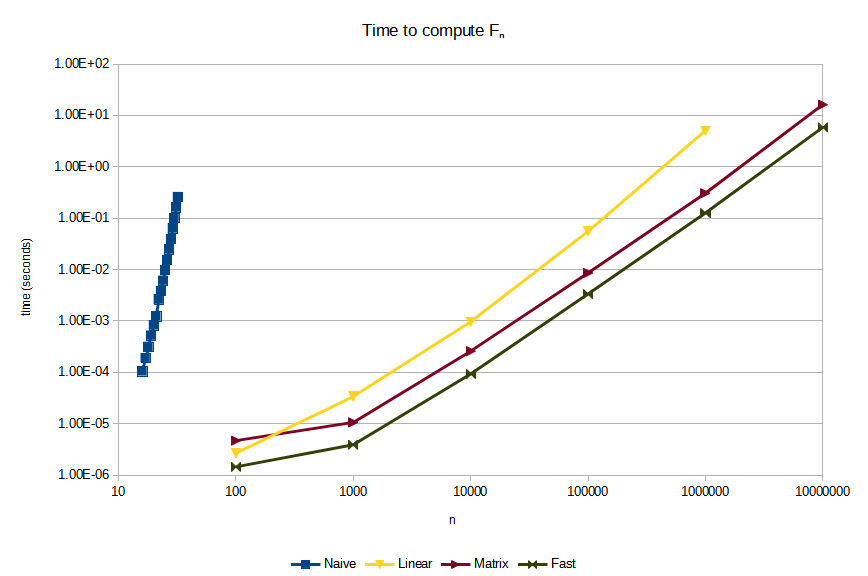
Some observations:
fibonacci_naiveis so slow that it doesn't even make sense to compare it to the other methodsfibonacci_linearis much better, but it is still asymptotically slower thanfibonacci_matrixandfibonacci_fast(although for smalln-- say, smaller than 250, it might actually be faster)fibonacci_fastis roughly 2.5 times as fast asfibonacci_matrix
Update (2024-01-26)
The Youtube channel Sheafification of G published several video's on efficiently calculating the Fibonacci numbers. At the time of writing, there are three videos which can be found in this playlist. In the second video, it is mentioned how one commenter gave a tiny Python implementation that, surprisingly, is faster than the C++ implementation from the first video. Here is the Python implementation:
def fibonacci(n: int) -> int:
def fib_pair(k: int) -> tuple[int, int]:
if k <= 1:
return (k, 1)
fh, fh1 = fib_pair(k >> 1)
fk = fh * ((fh << 1) - fh)
fk1 = fh1**2 + fh**2
if k & 1:
fk, fk1 = fk1, fk + fk1
return (fk, fk1)
return fib_pair(n)[0]
This is just a manual transcription of the code that is shown in the video at 0:41 with some slight modification in whitespace. I can't actually find where the code comes from, and for some reason you can't search in Youtube comments...
Notes:
fkis .fhis , I guess the "h" stands for "half".fk1is andfh1is .
I quickly compared this to the code I gave in this post and was pleased to see that this code uses the same idea, although I have to admit that this code is both more elegant and runs noticeably quicker. The differences are:
- It doesn't use the "accumulator" approach, but uses a more elegant recursive approach.
- It uses the recursion for and instead of for and like I do.
- It uses the exponentation operator (
**) instead of multiplication, and does some algebraic tricks to writefh**2 + 2 * fh * (fh1 - fh)asfh * ((fh << 1) - fh)to get rid of one multiplication.
All in all a worthy winner! I always believed that the "accumulator" approach was the fastest way to implement a Russian-peasant-style algorithm, and it's interesting to see this proven wrong.
Update (2024-01-27)
After thinking about this a bit more, I came up with the following version with is both shorter and faster:
def fibonacci_faster(n: int) -> int:
fk1, fk = 1, 0
for b in range(n.bit_length() - 1, -1, -1):
f2k1, f2k = fk**2 + fk1**2, fk * (fk + (fk1 << 1))
if n & (1 << b):
fk1, fk = f2k, f2k + f2k1
else:
fk1, fk = f2k1, f2k
return fk
It works by calculating either , or , , based on if the bth bit of the binary expansion of n is set. After the th iteration, fk will equal , where is the number that consists of the most significant bits of n.
Admittedly, it's not as nice to read as the recursive version.